From Prompt Crafting to System Design: The Rise of Context Engineering in AI
For years, the magic behind large language models (LLMs) like ChatGPT seemed to lie in prompt engineering—figuring out how to phrase a question or instruction just right. But as these systems have matured and grown more integrated into complex workflows, a deeper, more architectural discipline has emerged: context engineering.
Prompt Engineering: Asking the Right Question
Prompt engineering is the craft of precisely instructing an LLM to generate the right kind of output. You shape the tone, role, style, and logic—often using techniques like:
- Few-shot learning (providing examples)
- Chain-of-thought prompting (step-by-step reasoning)
- ReAct (Reasoning + Acting with tools)
Prompt engineering is essential for getting a model to do what you want. But as AI moves into production settings—support agents, research assistants, workflow automation—the limitations of prompt-only systems become clear.
What if the model forgets what just happened? What if it doesn’t have access to the data it needs? Enter context engineering.
Context Engineering: Designing the Model’s World
Where prompt engineering is about the input, context engineering is about everything around it. It answers the questions:
- What does the model already know before it sees your prompt?
- What tools can it access?
- How should it behave over time?
Context engineering includes:
- Agent identity and system instructions
- Memory (short- and long-term)
- External tools, APIs, and schemas
- Conversation history and retrieved knowledge
- Results from previous model actions
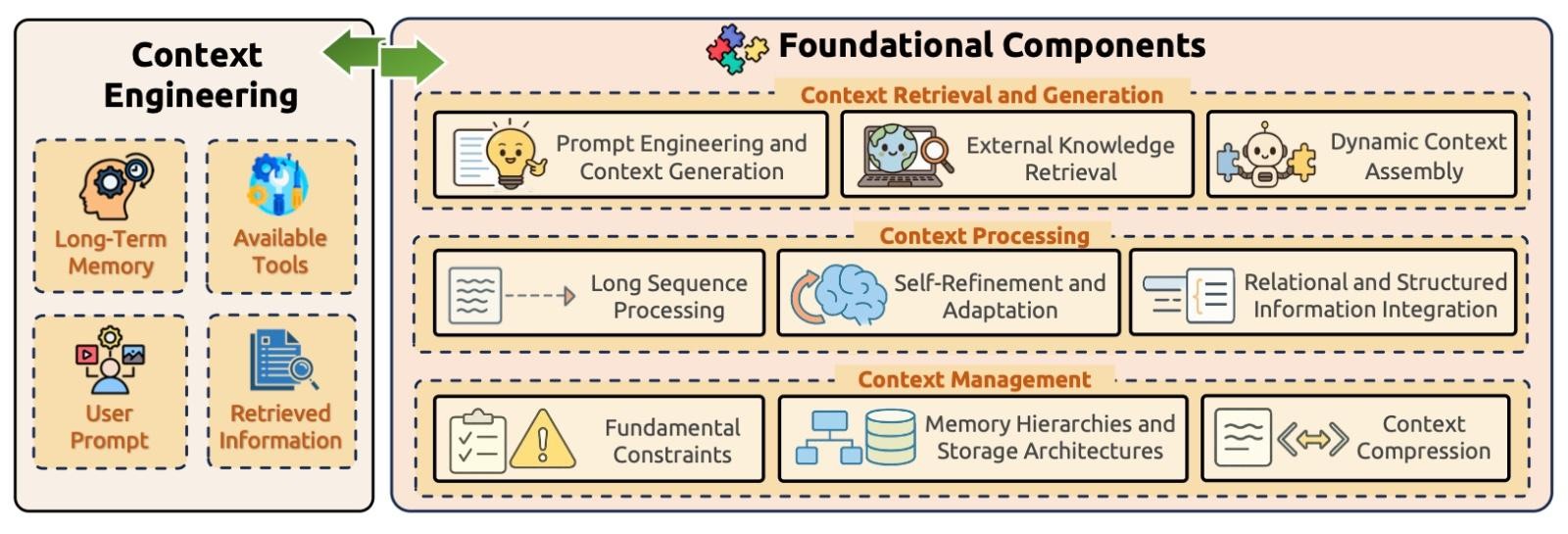
Source: A Survey of Context Engineering for Large Language Models
The Six Layers of Context Engineering
Think of designing a robust AI agent as building a stack of reliable layers. Each layer feeds into the model’s ability to act purposefully and consistently.
1. Instructions
This defines the AI’s role, goals, and guidelines:
- Who is the AI pretending to be? (e.g., a technical support agent)
- Why is it doing this? (e.g., resolve tickets empathetically and accurately)
- How should it operate? (e.g., tone, constraints, formatting expectations)
2. Examples
Behavioral and output examples help guide the AI, not just what to do—but what to avoid:
- Show preferred actions and good responses
- Highlight flawed behaviors for contrast
3. Knowledge
The background and reference material needed for intelligent reasoning:
- External: Company policies, product docs, knowledge bases
- Task-specific: Logs, specs, error messages, structured data
4. Memory
Context over time, crucial for conversations and ongoing tasks:
- Short-term: Current session (like remembering your last message)
- Long-term: Persistent data like preferences, interaction history, or procedural notes
5. Tools
APIs, search engines, calculators—any external capability that extends the AI’s powers:
- Each tool includes usage patterns, expected inputs/outputs, and micro-prompts for invocation.
6. Tool Results
What the model learns from using tools:
- API responses, search results, or outputs from earlier steps
- Fed back into the model to reason over and generate improved responses
Sample: Enterprise Support Agent in JSON
Let’s look at a simplified example of context engineering in action:
“Instructions”: {
“Role”: “Support agent with deep product knowledge and empathy”,
“Objective”: {
“Why”: “Resolve user issues quickly and accurately”,
“Deliverables”: [
“Troubleshooting steps”,
“Documentation references”,
“Escalation guidance”
],
“SuccessCriteria”: [
“Answer aligns with product guidelines”,
“Issue resolved or escalated”,
“Customer feels understood”
]
},
“Requirements”: {
“Tone”: “Empathetic”,
“Constraints”: [“No unsupported fixes”, “Escalate as needed”]
}
},
“Knowledge”: {
“ProductDocs”: “{{product_documentation}}”,
“CRMLogs”: “{{customer_ticket_history}}”
},
“Tools”: [
{
“name”: “getCRM”,
“description”: “Retrieve customer profile”,
“params”: [“customer_id”]
},
{
“name”: “searchKB”,
“description”: “Search knowledge base”,
“params”: [“keywords”]
}
]
Here, you see how the system defines role, access to memory, tools, and the kind of knowledge the model needs before generating a helpful support response.
Prompt vs. Context Engineering: A Side-by-Side
| Dimension | Prompt Engineering | Context Engineering |
| Scope | Individual input | Full AI runtime environment |
| Goal | Generate the right output | Support consistent reasoning |
| Scale | Manual per prompt | Systemic design across tasks |
| Failure Risk | Bad wording → wrong output | Lost context → hallucination |
| Skillset | Copywriting, UX | Systems thinking, architecture |
Where Context Engineering Shines
Prompting alone works fine for:
- One-off queries
- Simple creative writing
- Basic code generation
But context engineering becomes essential when you’re building:
- Conversational agents that remember you
- Workflow tools that interact with data
- Research copilots or product assistants
- Multi-turn planning or decision support systems
It’s the difference between a chatbot and an AI teammate.
Designing With Context in Mind
Effective context engineering means:
- Deciding what must be visible to the model each time
- Designing how to retrieve and structure that context
- Managing tool use, metadata, and output schemas
- Optimizing for latency, cost, and reliability
It’s not just about building smarter prompts—it’s about architecting smarter systems.
Summary
Prompt engineering is how you ask a great question.
Context engineering is how you build the world the question lives in.
Together, they enable AI agents that are helpful, reliable, and scalable.


