Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. Unlike traditional systems, Hadoop enables multiple types of analytic workloads to run on the same data at same time, at massive scale on industry standard hardware.
It’s at the center of an ecosystem of big data technologies that are primarily used to support advanced analytics initiatives, including predictive analytics, data mining and machine learning.
THE CORE COMPONENTS OF HADOOP
HADOOP HDFS
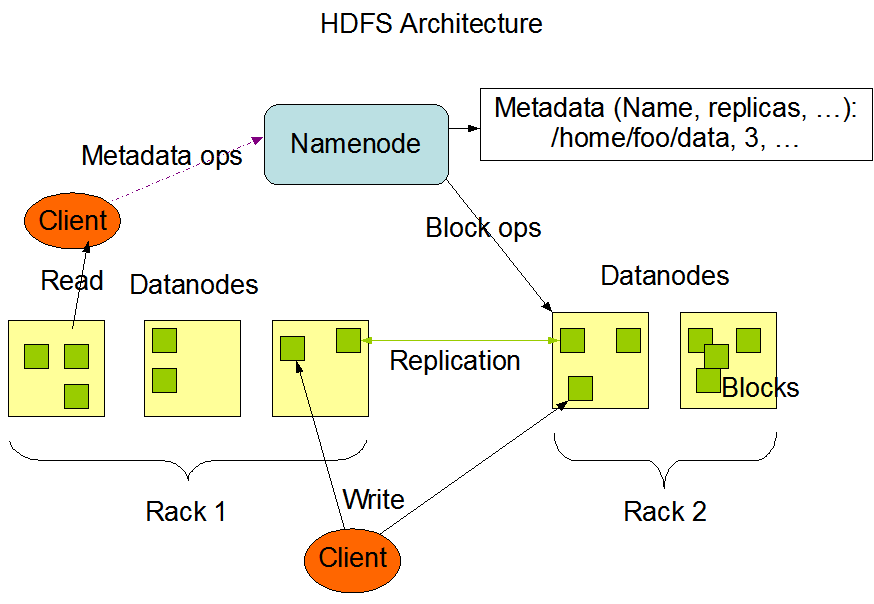
HDFS is the Hadoop Distributed File System. It makes it possible to store and replicate data across multiple servers to prevent the loss of data. The data is split into multiple blocks; each of these blocks has a default size of 128MB. Unlike other distributed systems, HDFS is highly fault tolerant and designed using low-cost hardware. HDFS follows the master-slave data architecture
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. Unlike traditional systems, Hadoop enables multiple types of analytic workloads to run on the same data at same time, at massive scale on industry standard hardware.
It’s at the center of an ecosystem of big data technologies that are primarily used to support advanced analytics initiatives, including predictive analytics, data mining and machine learning.
THE CORE COMPONENTS OF HADOOP
HADOOP HDFS
HDFS is the Hadoop Distributed File System. It makes it possible to store and replicate data across multiple servers to prevent the loss of data. The data is split into multiple blocks; each of these blocks has a default size of 128MB. Unlike other distributed systems, HDFS is highly fault tolerant and designed using low-cost hardware. HDFS follows the master-slave data architecture
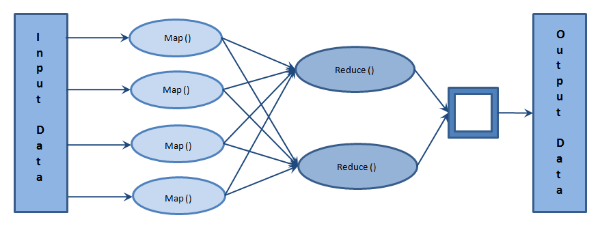
In Mapping, data in each split is passed to a mapping function to produce output values. In Shuffling, consumes the output of mapping phase. Its task is to consolidate the relevant records from Mapping phase output. In Reducing, output values from the Shuffling phase are aggregated. This phase combines values from Shuffling phase and returns a single output value. In short, this phase summarizes the complete dataset. Reduce task should begin after the completion of the map task.
HADOOP YARN
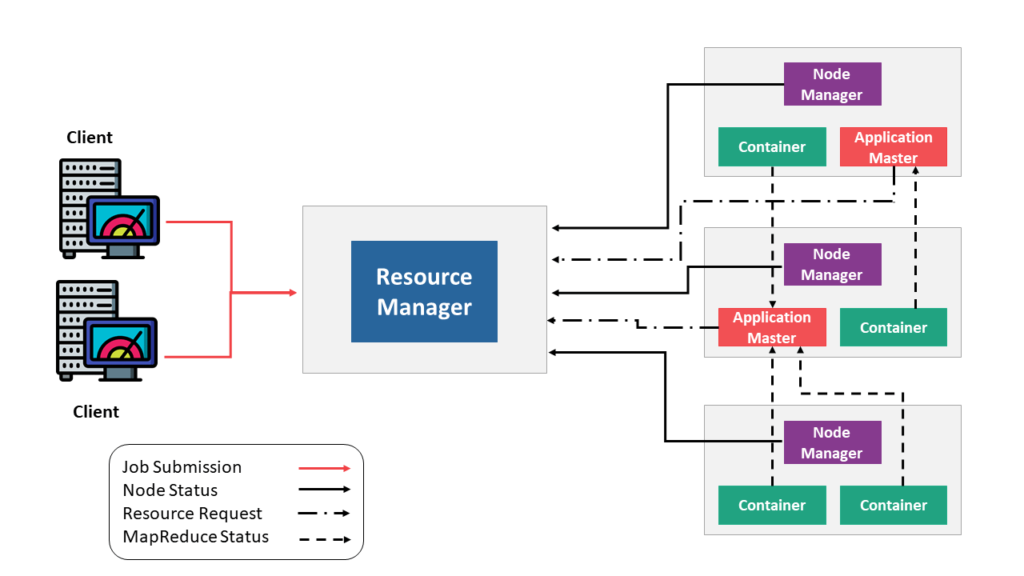
YARN stands for Yet Another Resource Navigator and is the resource management and job scheduling technology in the open source Hadoop distributed processing framework. YARN is responsible for allocating system resources to the various applications running in a Hadoop cluster and scheduling tasks to be executed on different cluster nodes.
YARN consists of:
- Resource Manager – It is the master daemon of YARN and is responsible for resource assignment and management among all the applications. Whenever it receives a processing request, it forwards it to the corresponding node manager and allocates resources for the completion of the request accordingly.It has two major components : 1. Scheduler 2.Application Manager
- Node Manager: It takes care of individual node on Hadoop cluster and manages application and workflow and that particular node. Its primary job is to keep-up with the Node Manager. It is also responsible for creating the container process and starts it on the request of Application master.
- Application Master: An application is a single job submitted to a framework. The application manager is responsible for negotiating resources with the resource manager, tracking the status and monitoring progress of a single application. The application master requests the container from the node manager by sending a Container Launch Context (CLC) which includes everything an application needs to run. Once the application is started, it sends the health report to t he resource manager from time-to-time.
HADOOP FEATURES
Some of the main features are:
- Fault Tolerance
- Reliability
- Scalability
- High Availability
- Economic
- Data Locality
For More Reference: https://www.simplilearn.com/hadoop-tutorial-article?source=frs_category

